What is Computer Vision – Post 6: Artificial Intelligence
January 20, 2017
What is Computer Vision – Post 6: Artificial Intelligence

(Image from: Slator.com)
This is the sixth in a series of 8 posts looking at computer vision for non-technical people. The previous post was a quick history of computer vision. A key point from that post was how recent breakthroughs in computer vision have been driven by breakthroughs in artificial intelligence (AI). Well, now the time has come to cover AI in more detail.
First off, let’s list the artificial intelligence challenges to achieve computer vision:
-
Discrimination: this is a dog but that’s a wolf.
-
Commonality: these things look somewhat different but they are actually both desks.
-
Rotation: this car is upside down for some reason but it’s still a car.
-
Occlusion: I can see half of that kitten but I still know it’s a kitten.
-
Lighting: the light is low but I can still see that’s a tree.
If it’s not intuitively obvious that these five challenges are difficult, then take the dog or muffin test below:

(Image from: Artificial Intelligence Online)
What this shows is that even very different real world objects can look pretty similar, and that you have to get quite detailed to articulate exactly what the consistent differences are.
The recent advances in artificial intelligence that have enabled us to start to meet the challenges above have all come from a specific area of AI -- deep learning.
Here, very broadly, is how deep learning works. There are four phases:
-
The training phase
-
Input
-
Analysis
-
Output
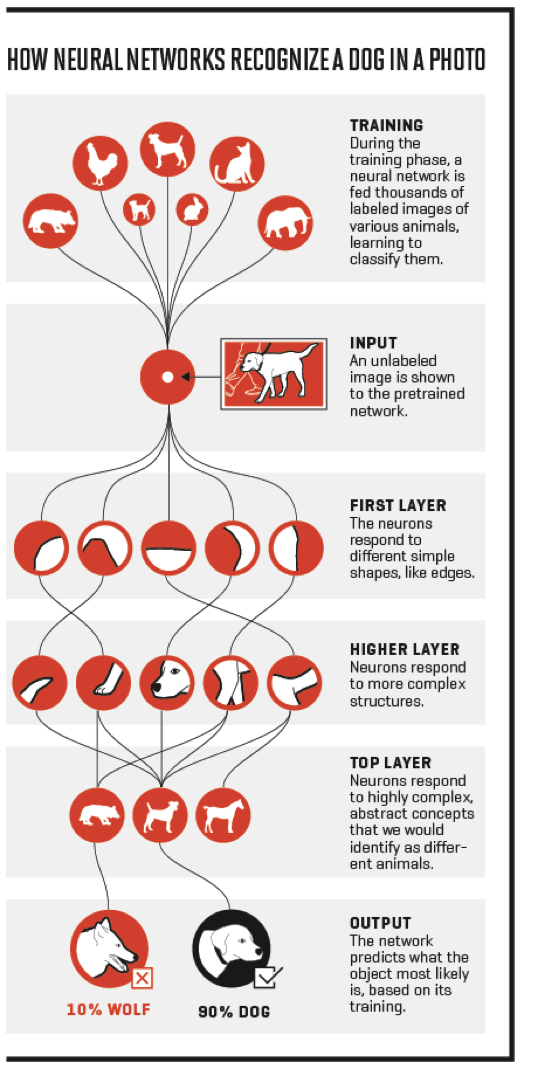
(Image from: Fortune.com)
In the training phase, you are teaching the computer what something looks like. For instance, babies can learn what a cat is having only seen one a few dozen times (Source: seeing my son do this!). Computers aren’t that smart yet: they require massive data sets with millions of examples to learn to identify something like a cat.
The training process happens through neural networks. We covered these briefly in the previous post and now’s the time to delve a bit deeper. A neural network in computing is analogous to and inspired by the networks of neurons in human brains. The key thing about them for our purposes is that they are a self-organizing form of learning. Learning happens through pattern recognition not by applying a pre-programmed set of rules or logic. Pioneer Geoffrey Hinton first saw AI potential in artificial neural networks because he observed that, whereas logic doesn’t appear in kids until they are 2 or 3, pattern recognition happens way sooner. He reasoned that as a result neural networks could forge a better path towards computers self-learning than other methods being explored at the time.
Once the neural networks have had a chance to learn, you’re then ready to feed the system new images. This is the input phase.
The next phase – analysis – is what makes deep learning “deep”. We came across the Perceptron in the previous post. This had only one “layer” but today neural networks can have dozens, and in rare cases, even hundreds of layers. Essentially lower layers deal at the micro level of the image and higher levels deal at macro levels. The lowest levels look at how individual pixels connect to form different shapes and edges. The next layer starts the process of integrating these findings, e.g. “These edges connect”. The top layer integrates the components together and is able to compare abstract shapes with those learned in the training phase. The output phase, the final phase, consists of a probabilistic prediction as to what the object is, based on what the system learnt during the training phase.
Some of the recent advances have resulted from more theoretical breakthroughs. But probably, these theoretical breakthroughs and the improved algorithms they’ve engendered have been less important than two other factors:
#1. Lots and lots of data. As we covered in the previous post, deep neural networks need lots and lots of data to learn effectively in the training phase. Access to data in large quantities is way easier today than in the past as so much is online.

(GPUs: designed for games, awesome at computer vision processing. Image from Screenrant)
#2. The final factor in recent advances is the graphics processing unit, or GPU. This is a microchip originally developed for gaming platforms in order to make graphics render quickly and realistically in games. It turned out that an unexpected but welcome side effect has been that GPUs are much better at the type of processing on which computer vision depends. Versus other chips, GPUs can be up to 30x better. Together with tons more data, this improved processing capability has made a big difference.
In the next post we will give an overview of some of the use cases for computer vision.
In writing this article, I have called on this excellent summary on recent AI breakthrough in Fortune.



